
Data Scraping and Mapping Methods
As is the case with all of FracTracker’s projects, we feel it is important to be transparent about our methods. This page details how we obtained and made sense of oil and gas data presented on the interactive map. Many of the methods are based upon a previous iteration of the project completed in 2016 with the assistance of the software development company West Arete.
ⓘ As stated in the disclaimer, FracTracker cannot provide any assurance that the information provided in this lease records database or the resulting maps is accurate, reliable, or up to date. In addition, the information in this lease records database and the resulting maps should not be considered an assessment of property rights, nor should anyone consider the content within this database and the resulting maps as legal advice. The methods we used and the information obtained was done to the best of our abilities as workers of maps and data.
Obtaining the Data
Preliminary Research
FracTracker’s Lease Mapping Project is not the first attempt to get a comprehensive view of oil and gas leasing activity in Allegheny County. A similar effort was made by the University of Pittsburgh’s University Center for Social & Urban Research (UCSUR) in 2010, but changes in the county’s data structure made updating this for several years. Much has changed since that original map was released, but UCSUR was an invaluable resource for the first iteration of this project in 2016, both in terms of comparing our results, but also by being willing to discuss experiences and challenges that they faced along the way. Several key operators would have been missed from the current effort if it weren’t for the work they had done. You can read more about the previous UCSUR research here.
The Scraping Process
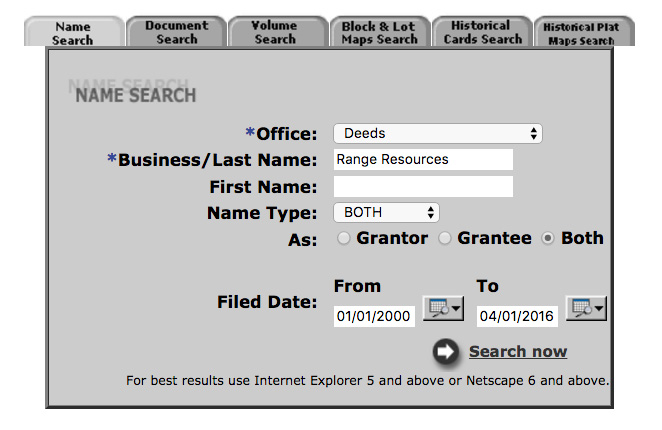
To scrape the data, we used to create the interactive lease map, records were pulled from the Allegheny County’s Department of Real Estate Office website. We created an automation program that selected Office of Deeds from the search page, entered one of the “free search” terms into the Business/Last Name text field, selected both Grantor and Grantee related records, and set a date range beginning on 1/1/2000.
The “free search” term came from a list of names generated by FracTracker from a variety of sources. This information included oil and gas companies listed by the Pennsylvania Department of Environmental Protection as either having an oil and gas well or a permit for a well. The list also included names of known land agencies, pipeline companies, and other operators listed on industry sites such as this one.
The program then visited each entry in the Search Results Index. This process would yield a “Document Index” for that spelling of that operator, from which the program would then visit each search results page in the Document Index.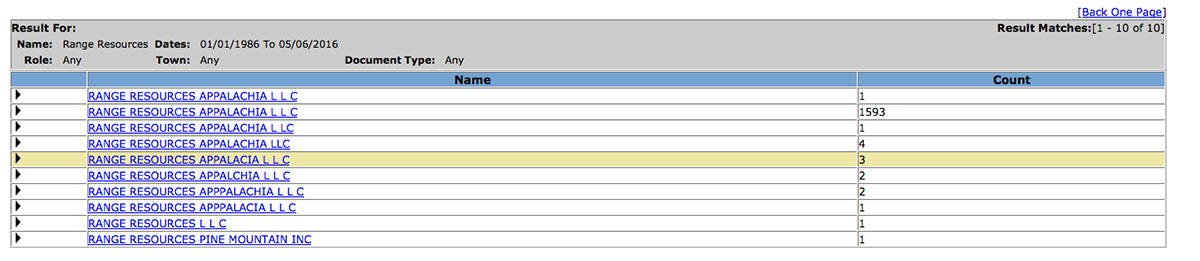
There are many spelling variations and occasional misspellings in the documents. For example, Range Resources may be listed as “Range Resources Appalachia L L C,” or “Range Resources Appalachia LLC,” etc. To account for these inconsistencies, we manually devised a list of free term variations that would match all of the relevant records for that operator, while trying to minimize false positives. Due to these variations, sometimes it was necessary to use multiple search terms to match all of the records for one operator. The automated program would then visit the Allegheny County website, perform the searches, and download the results into a Search Results Index.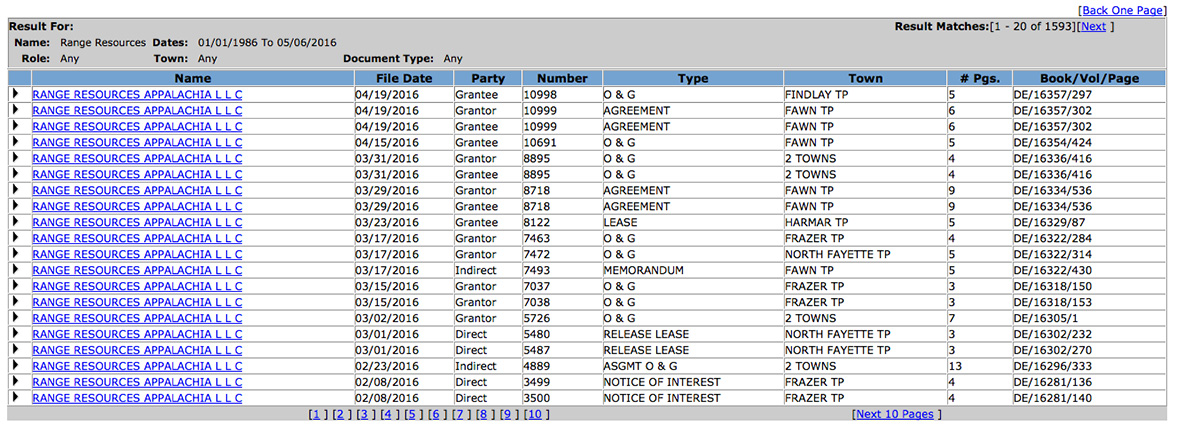
Each record in the Document Index would have a link to a Document Page. To continue the process, we needed a Block/Lot number (the number associated with each unique parcel in the county) in order to place the document on a map. Some documents would have a Block/Lot number and others would not. The program visited all Marginal Reference Documents (other documents associated with that parcel besides the one being viewed), including multiple levels of Marginal Reference Documents, to search for documents that had the Block/Lot number.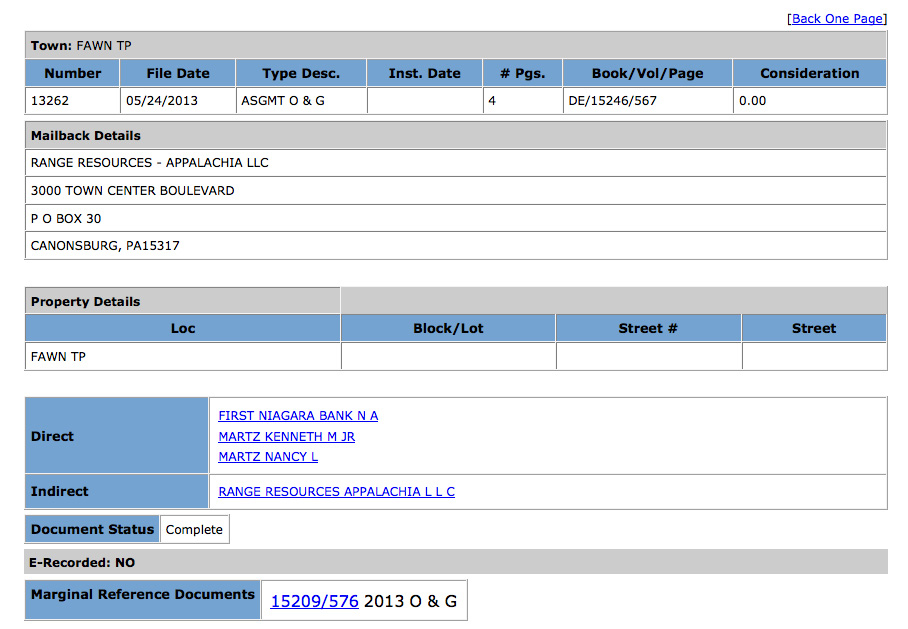
For each page, we would download the source of the page to disk, as well as maintain a record of its original URL on the County’s website, and any Marginal Reference Documents to which it might link. We used a unique document identifier present in the URL (“Number”) to check if the program had already visited and downloaded any given document. This technique allowed us to avoid re-retrieving any previously seen documents.
Parsing the Data
After all of the Documents had been downloaded to disk, the content of each one was parsed for all of its relevant metadata. Such metadata included the document’s number, date, and type. The list of Block/Lot numbers was saved, as well as the list of grantees and grantors. Because a document can link to others through its Marginal Reference Documents section, after this section was parsed, any documents linked to in this section may have to be retrieved, downloaded to disk, and parsed themselves. Thus, obtaining data for a particular operator was an iterative process: perform a search, download the initial set of documents, parse them, download any linked documents, parse them, and repeat until no new documents were found. All Document data was included in the database, and because we retain all the source code on disk, additional metadata can be parsed in the future if necessary.
Standardizing Block/Lot numbers
To display the parcels spatially, we needed to match the documents we scraped against a GIS-oriented shapefile containing all of the parcels in Allegheny County. The Block/Lot number provides us the means to do this, but the formatting in the documents did not match that of the shapefile. A Block/Lot written in a document like “123A456” may be referenced on the County’s Real Estate as like “123-A-456” and referenced in a shape file using its full-form Parcel Identification Number (PIN) “0123A00456000000.”
Additionally, there was some ambiguity in the formatting of the Block/Lot encountered in our documents. For example, one document listed the block lot as “1839K247 1.” Block lots in this format can be interpreted in PIN format as either “1839K00247000100” or “1839K00247000001.” In this particular case the latter interpretation is correct, but other documents containing block lots in a similar format only matched the former. There is no way of knowing the correct formatting of this type of Block/Lot without explicitly checking the various potential candidates against the shapefile itself.
The shapefile for all parcels in Allegheny County contains over 230,000 parcels, a large number to check every document against. To overcome this size limitation we utilized python libraries to asynchronously parse all the PIN combinations in the shape file and select the correct one. Once the Block/Lot numbers were resolved into valid PINs, filtering and mapping the parcel shape file to only those parcels mentioned in our Documents was possible.
Importing Additional Parcel Information
Other parcel metadata is useful for exploring this data. Municipalities, school districts, zoning types, and market values all enrich the narrative. Because we were able to resolve our documents’ block lot numbers into PINs, joining this metadata to our database was possible. It did require reformatting the text to be suitable for display, but otherwise it was fairly painless. We obtained this additional metadata from the county.
Converting Variations to Canonical Names
Among the data extracted from the land record documents, there was a large variability in the terms used within them. As mentioned above, a particular operator such as Consol could be referred to in the documents variously as “CONSOL GAS CO,” “CONSOL PA COAL CO L L C,” and “CONSOLIDATION COAL CO.” We looked through the data to resolve these variations among all known operators to collapse them down to one common or “canonical” name. Both the “verbatim” search term and the canonical name are stored in our database. Likewise the document “type” exhibits large variability. We collapsed several of these terms into one for ease of searching. For example the document types “O & G,” “AMEND O & G,” and “LEASE” are all displayed as the canonical form “O&G Lease.” Both the verbatim document type and canonical are stored in our database. The canonical terms are mainly used for simplifying the user interface. However, when a particular parcel is clicked, the verbatim terms are presented to the user. See our Understanding Lease Records page for more information on this process.
Redacting Private Names
Although the land records documents are public, and available for viewing on the County website, we chose to redact the name of any party that was mentioned on one and only one document. As this information is public, those interested can access it on the land records site.
Eliminating Irrelevant Documents
While we saved every document obtained in our original searches to our database, only certain document types are appropriate for viewing in the context of oil and gas agreements. For example, affidavits and bankruptcy records are not especially relevant and are eliminated from the dataset used to construct the parcel histories seen on the interactive map.
Bringing Data into the Map
Export the Data Keyed to Block/Lot Number
The next step in the process was to export a CSV file where each row represents a single document. These rows are keyed against the normalized block lot numbers. This means that a single block lot number may have many rows referencing it: one row for each document that is attached to that block lot. This data includes document metadata such as grantees, grantors, the search term that generated that document, municipality, school district, and general zoning designation.
Join The Data with Block/Lot Shape File for Allegheny County
The shapefile contains a shape for every parcel in Allegheny County (approximately 230,000 shapes). We took our list of formatted block lot PIN numbers and joined it with our shapefile so that we only have shapes for parcels which we also have document data. This process resulted in approximately 33,000 shapes for Allegheny County.
We also joined each shape to our metadata, so that we can search and filter the displayed shapes based on various options. This is what allows the interactive map to do things like display only parcels that have an O&G Lease, or parcels in a particular school district.
Load Shape-Based Data into a Django Web Application
We then uploaded this shapefile to an AWS PostgreSQL Database so that it could display the shapes of Block/Lots for which we have document data on an interactive Leaflet map. The well layers are all point-based data (as opposed to block lots, which are represented as polygons). The source for this data set is the PA DEP. This data also resides in the same database with one row for each well site, and two columns that represent the point’s coordinates. Other columns describe the well type, etc.
Recognizing Limitations
We approached the data scraping, parsing, and mapping work with a conservative eye in order to avoid over-representing the scale of oil and gas activity in the region. That said, we also recognize a number of limitations in our methods.
First, we believe our methods were successful in eliminating the vast majority of irrelevant records, but we acknowledge that there is still a marginal level of noise in the data. For instance, some oil and gas drilling companies such as Peoples Gas are also public utilities. We did our best to narrow records in the system pertaining to public utilities down to those that were specifically related to oil and gas development. That said, we recognize that a few documents outside that scope may remain in the dataset.
Second, our intent with this project was to capture leasing activity primarily due to the recent wave of unconventional oil and gas development. For this reason we set our date range to begin at 1/1/2000. Looking at the map one finds a number of additional oil and gas wells without corresponding leases associated with the parcel. Many of these are conventional wells with leases signed prior to 1/1/2000.
Missed Records
Third, we recognized that there are parcels likely under some kind of oil and gas agreement that were not captured with our methods. Missing records are partly due to the County’s website providing no way of knowing all the naming variations of a particular operator, nor the sum of operators in their database. We were forced to manually construct our list of suspected operators based on our knowledge of the industry. Some search terms we simply missed.
Despite these known limitations, we feel confident that our methods were extremely efficient in capturing a significant portion of oil and gas agreement activity in the county given the tools and data at our disposal. Nevertheless, the Allegheny Lease Mapping Project is a reverse engineered system. If there is one takeaway from the project it is that public information on oil and gas leasing activity is far from accessible, but is trending in the right direction with some data being backfilled.